Semantic SLAM 相关方案调研
Published:
Semantic SLAM 相关方案调研.
高精地图语义定位
论文提出基于高精地图和语义特征的视觉主义定位算法。在城市道路环境中,语义特征易于提取,并且对光照、天气和视角等变化有着一定的鲁棒性。针对语义特征关联问题,提出了鲁棒关联算法,充分考虑了局部结构一致性、全局模式一致性以及时间序列一致性。另外,提出了基于滑动窗口的因子图优化框架,对特征关联结果以及里程计信息进行融合与优化。
方法流程
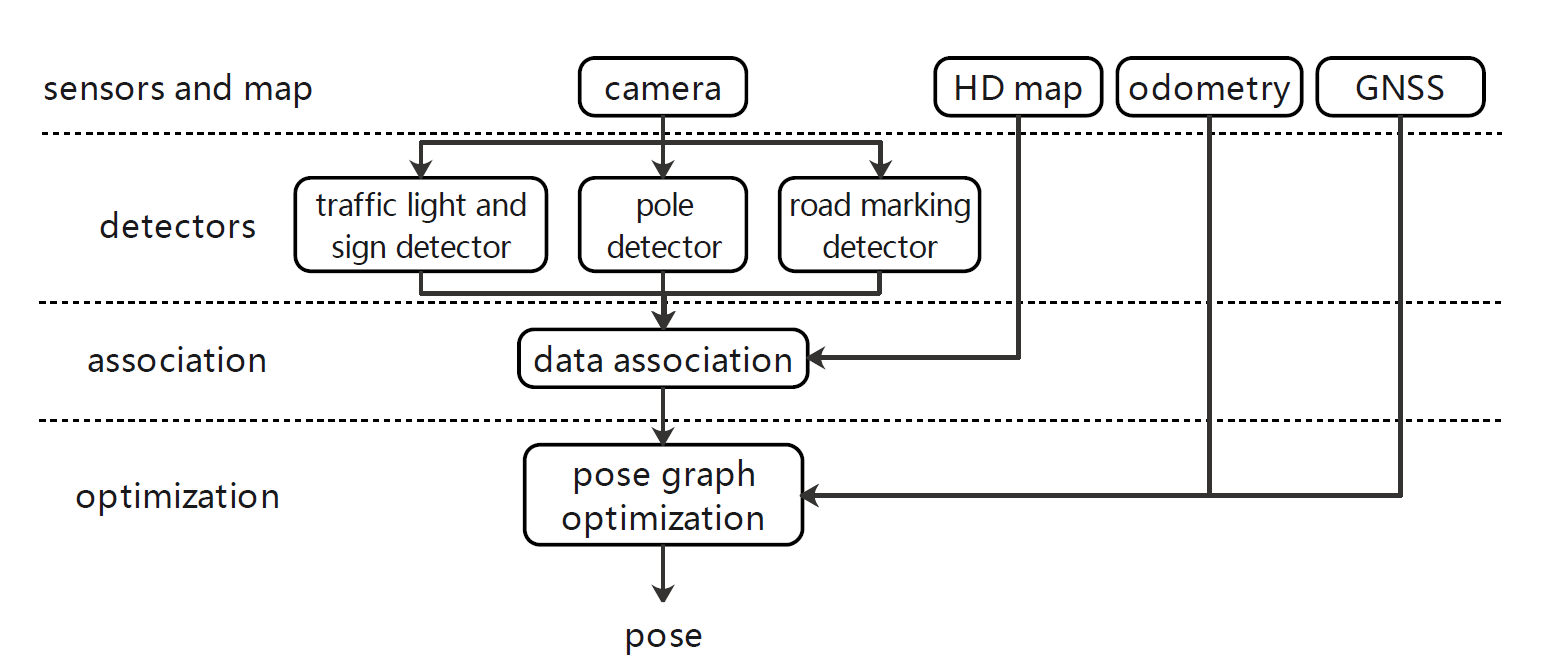
视觉图像语义特征提取:
- 这使用卷积神经网络方法YOLOV3,提取道路标识、电线杆、交通灯和指示牌作为语义特征。提取出的语义特征描述子为\(s_t=(s_t^l,s_t^c,s_t^b)\),其中\(s_t^l\)表示语义类别,\(s_t^c\)表示置信度,\(s_t^b\)表示特征的几何描述信息。
与高精地图的语义特征关联:
在先验位姿附近采样生成候选位姿,对于每一个候选位姿,进行地图特征到当时图像帧的投影。
基于局部结构一致性的粗关联过程,根据特征在横向位置的分布情况,去除明显的误关联结果。
对粗关联结果进行进一步优化,融合匹配数据、匹配相似度和局部结构相似性等信息,得到最优的全局一致关联结果。
在时间相邻的图像序列上对特征进行跟踪。
通过时间域平滑过程,得到时间一致性的特征关联结果。
位姿图优化:
- 对于滑动窗口内的帧,使用非线性优化方法对位姿估计结果进行优化。具体误差项包括:里程计误差、观测重投影误差和地图特征匹配误差。
关键技术
算法提供基于高精地图和语义特征的定位方案,在进行局部地图构建的同时,完成局部地图特征与第三方高精地图特征的关联和匹配,为语义SLAM建图结果适配第三方高精地图的需求提供了一种可选的解决方案。
算法提出了具有时空一致性的语义特征关联方法,针对不同类型的语义特征,如果交通信号灯、指示牌等,采用不同的高层特征描述方法。
通过往图优化算法中加入提取特征与地图特征的匹配情况,完成基于高精地图的定位。
性能分析
算法在30km范围的城市道路中,可以达到0.43m的纵向定位精度,0.12m的横向定位精度,以及0.11deg的俯仰角精度。
算法主要依赖于低成本传感器,满足传感器成本的商业化需求。
论文未涉及实时性评估,并提到在未来工作中希望扩展框架来实现实时定位,因此推测目前算法不具备实时性。
轻量语义地图定位
针对自动驾驶领域依赖于高精度传感器和高精地图的现状,论文提出轻量语义地图定位方案,使用低成本传感器以及轻量视觉语义地图完成定位。地图中包含若干语义元素,例如车道线、人行横道线、停车线等等。论文提出了车端建图、云端维护以及用户端定位的框架。建图所需数据是由车端传感器进行采集以及预处理,然后上传到云端服务器进行信息融合,并更新语义地图,最后语义地图经过压缩后,再传到用户端并用于用户车辆的定位。
方法流程
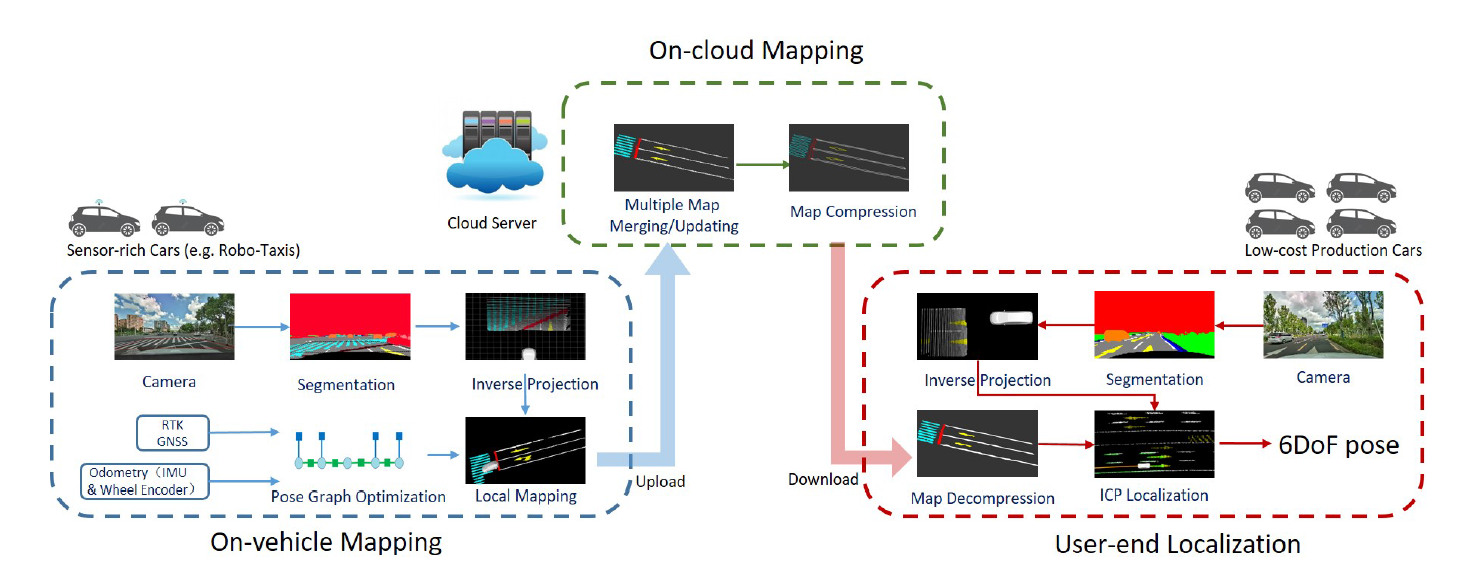
车端建图算法:
使用CNN方法进行图像的语义分割,分割类别包括:地面、车道线、停止线和道路标线。
对于分割结果,通过逆投影变换将带有语义标签的地面像素点投影到车体坐标系。
通过因子图优化算法,融合了里程计约束和GNSS约束,对车体位姿序列进行优化。
使用图优化得到的车体位姿结果,将语义特征从车体坐标系变换到全局坐标系,完成车端的局部建图。
云端建图算法:
地图融合与更新。云端服务器接收不同车端的局部建图结果,并根据车体位置对地图进行融合与更新。地图是以栅格地图的形式进行保存,栅格大小0.1×0.1×0.1m。
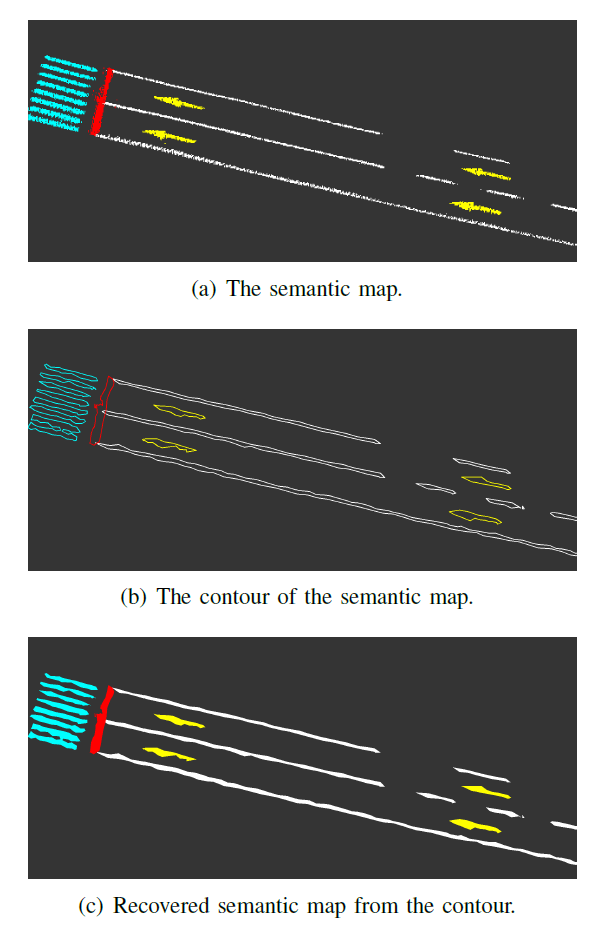
地图压缩。考虑用户端有限的传输带宽和车载存储,云端对地图进行压缩后发送给用户端使用。地图压缩是通过轮廓提取完成的,如下图所示。
用户端定位算法:
用户端车辆搭载低成本传感器,例如摄像头、低精度GPS、IMU以及轮速计。
地图解压缩,即利用从云端下载的压缩地图中的轮廓信息,对语义地图进行恢复。
使用ICP匹配算法进行定位,并使用EKF算法对视觉定位结果与里程推算结果进行融合。
关键技术
算法利用云端服务器对多车端的建图结果进行融合,生成全局语义地图,一方面有利于使用多个车端进行较大规模的地图构建,另一方面也利用了云端服务器更好的处理性能和存储空间。
用户端使用从云端下载的压缩地图进行车体定位,可以更好地适应用户端的低成本传感器配置。
算法提出基于轮廓信息的语义地图压缩方法,可以使地图的传输更加高效。
性能分析
算法在22km的城市道路上进行建图,原始语义地图的大小为16.7MB,压缩语义地图大小为0.786MB,平均36KB/KM。
基于建图结果,x轴平均定位误差为0.043m,y轴平均定位误差为0.040m,yaw角平均误差为0.124deg。
轻量语义网格建图
论文提出轻量语义地图构建方案,直接使用单目或双目相机,以3D网格的形式构建轻量语义地图,融合传统基于特征的视觉里程计方法以及深度预测、语义图像分割方法,对语义相关的环境结构进行识别和重构。通过概率融合框架,使用语义标签增量式优化和拓展3D网格结构。
方法流程
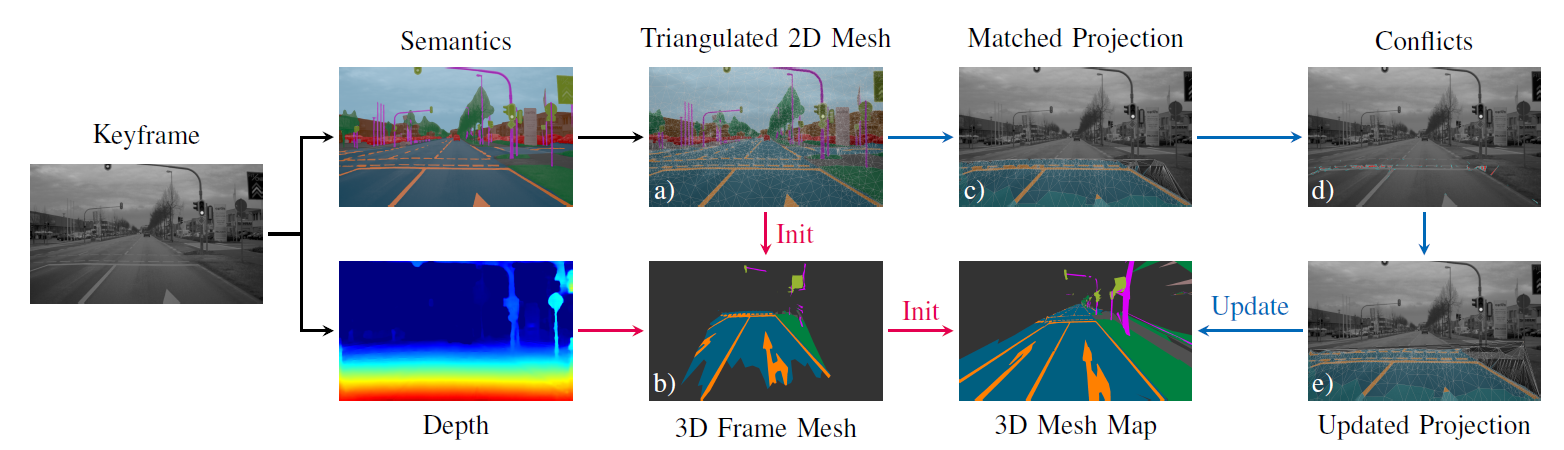
系统使用ORB-SLAM2作为视觉里程计,并利用其输出的关键帧作为建图系统的输入。基于视觉里程计的结果,建图系统进行增量式网格地图构建,每一个更新步骤的输入为经过语义分割和深度计算的关键帧图像,输出轻量语义网格地图。
关键帧图像语义分割与深度计算:
- 使用PSPNet算法对图像进行语义分割,像素对应深度值可以通过双目视觉或者深度预测算法进行计算。
单帧网格结构提取:
基于已知的单帧数据语义分割结果,提取2D三角网格结构\(M_F=(V_F,F_F)\),其中\(V_F\)表示2D节点,\(F_F\)表示面片元素,每个面片均以分割得到语义标签来进行标记。对于提取结果中面积较大的三角面片,进一步进行Delaunay分割,使得三角网格中每个面片的边长与夹角都控制在一定范围内。
通过将语义标签相同的面片进行聚类,得到语义结构单元,并针对边缘处深度值计算准确性不高的区域,根据聚类结果对深度值的计算结果进行进一步地优化。
网格地图初始化:
- 基于计算的深度值信息,可以将2D三角网格M_F转换为3D网格\(M_M=(V_M,F_M)\),并计算节点的空间不确定性,以及每个3D面片的语义标签。
语义网格匹配:
- 将当前帧提取的网格结构与网格地图进行匹配,具体而言,将地图中的3D网格节点投影到当前帧的2D图像中,并与当前帧中提取出的2D网格进行匹配。考虑节点在空间的不确定性,匹配误差定义为2D节点之间的马氏距离。
语义网格融合:
基于当前帧提取的2D网格结构与3D网格地图的匹配结果,利用当前帧提取的网格分割结果M_F对3D网格地图M_M进行更新。
找到地图中与当前帧网格具有匹配关系的网格结构,并将其投影到当前帧图像平面上。
在具有匹配关系的当前帧网格以及重投影地图网格结构中,找到具有不同语义标签的网格面片,定义为冲突结构,并利用这些冲突结构,对地图网格中的语义标签进行相应的更新。
基于匹配网格结构的节点位置以及深度估计,对地图中网格节点的分布进行更新。
关键技术
算法采用带有语义标签的三角网格结构作为地图的表达形式,相比于栅格结构的地图,三角网格划分具有更高的灵活性,甚至能够直接通过网格结构的合并,进行语义物体的划分。相对地,其劣势是会消耗更多的存储空间与计算资源。
在进行地图匹配与更新时,重投影过程采用3D到2D的投影,匹配过程是在2D空间中完成,再通过2D到3D的投影,来完成地图的更新,这样一来,可以在匹配的过程中降低运算量,而在地图更新的过程中保留地图的三维空间结构。
算法性能:
论文对语义标签的准确率、召回率及F-Score进行统计,对于不同类别的语义标签,F-Score值的范围为50.1-89.5%。
建图算法的运行时间为平均每帧200ms。
稀疏语义特征建图与定位
面向自动驾驶问题,提出基于语义道路元素提取、建模和优化的视觉建图和定位算法。不同于传统的点特征,算法使用级联式深度模型,检测标准化道路元素,并针对不同类型的元素进行特征参数化。基于道路语义特征,建立完整的建图与定位系统,包括前端图像处理、传感器融合策略以及后端优化。
方法流程
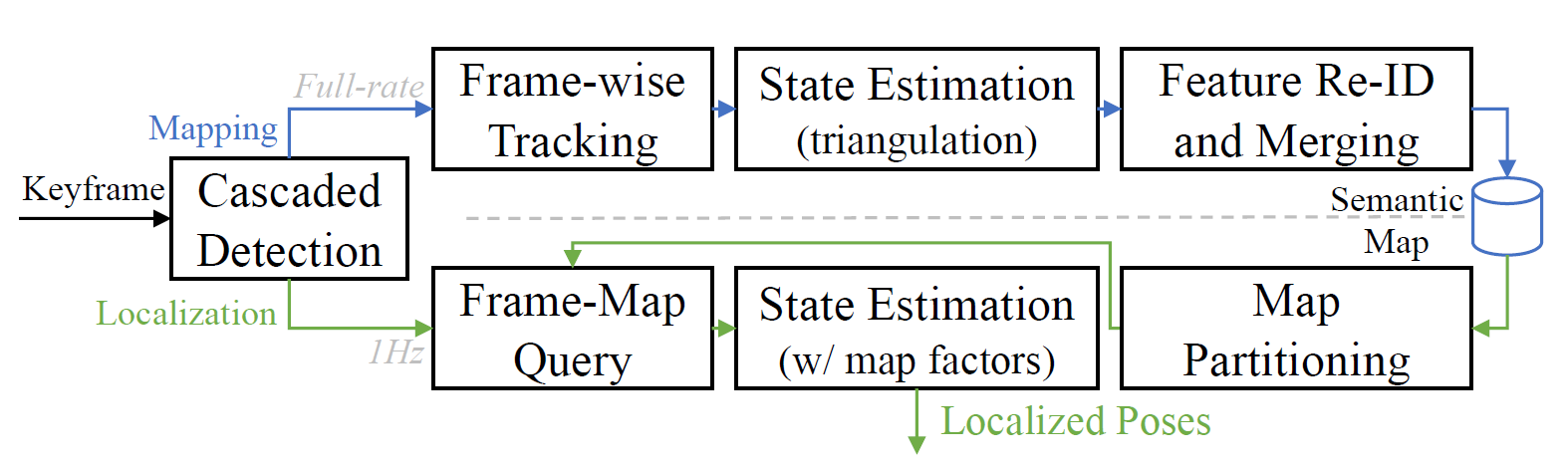
系统采用离线建图与在线定位策略,构建的地图中包含三种主要类别:1. 路灯和交通信号灯等在直立杆上,容易被前置相机捕捉到的物体;2. 路面标识;3. 车道线(包含实线和虚线)。
在离线建图的过程中,对每一个关键帧进行语义特征的提取与跟踪,并进行多帧数据关联,以及对相机轨迹与特征位置的联合估计。接着,通过闭环检测的方法,对重复观测的语义元素进行再识别与融合。
对于在线定位过程,特征提取模块以较低速率运行,以适应低成本计算单元。通过特征提取与跟踪策略得到语义特征的估计结果,并将其应用在基于里程计系统的滑动窗口优化中,从而减少全局的漂移现象。
道路特征提取:
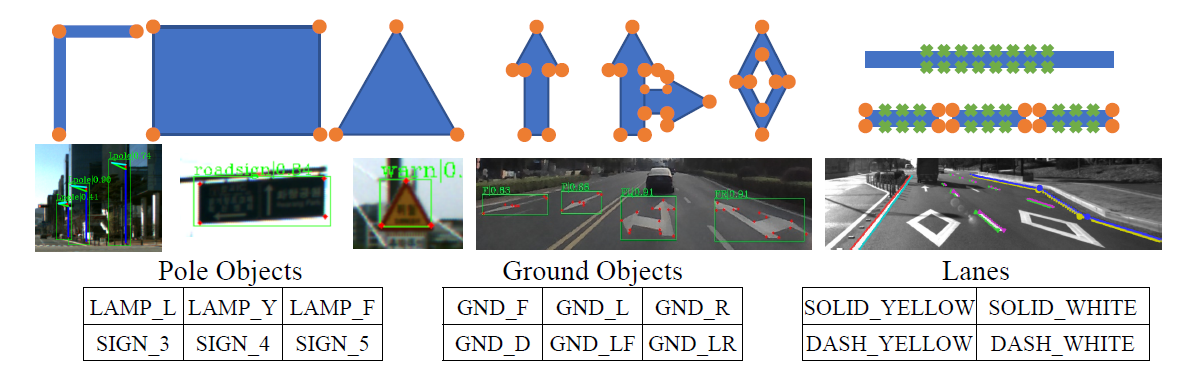
- 使用CenterNet特征提取方法,对于特征形状的语义元素,提取其代表性索引像素,而对于车道线,则在线轮廓处采样得到一系统采样像素,作为语义特征的描述。对于虚线型的车道线,则进一步提取虚线角点索引像素。下图给出了几种特征描述的示意图。
语义特征跟踪算法:
通过IMU预积分得到两帧之间的相对位姿变换\(T’\)。
对于地面平面上的语义特征,使用重投影方式将一个像素点\(p\)投影到另一帧\(p’\)。
使用Hungarian匹配算法对地面特征分别进行物体级与像素级的关联。物体级关联通过计算交并比来完成,而对于像素级关联,则是通过像素之间的重投影距离进行关联。
使用光流法对提取出的特征点进行跟踪。
状态估计方法:
基于提取与跟踪的语义特征,在优化的因子图里加入三种约束:
特征点观测因子,即语义特征点的重投影误差。
样条曲线观测因子,即样条曲线上采样点的重投影误差。
先验共面因子,即语义特征点之间的共面约束。
关键技术:
算法提供语义特征参数化方案,对于不同类型的特征,采取不同的参数化方法,例如,对于特定形状的标记,提取结构特征点对其进行表征,而对于车道线,则在轮廓线上进行采样,并拟合样条曲线进行参数化。
在优化因子图中,根据语义特征的类别,加入不同的约束因子,以及针对地面上语义特征之间的共面约束,共同进行优化。
算法性能:
在KAIST-38数据集上的实验结果,对于1.54MB的地图,可以达到0.46m的定位精度,相比而言,传统方法7.60MB的地图只能达到0.75m的定位精度。
在定位模块中,平均的算法运行时间大概为300ms,即能达到3Hz的运行速率。
语义点云配准框架
代码:unified_cvo
论文提出非参数化刚性点云配准框架,对几何与语义的观测信息进行联合优化,例如颜色信息、语义标签信息等,并且不需要进行显式的数据关联。将点云表示为再生核希尔伯特空间中的非参数函数的形式。在点云的匹配过程中,最大化两个函数之间的内积,即加权核函数的和,每个加权核函数都融入了局部的几何信息和语义特征。由于是连续函数模型,因此能够解析地计算梯度,通过在刚体变换群上的优化,可能得到局部解。另外,考虑几何信息和语义信息,提出新的点云匹配度量方法。
算法原理
点云匹配问题定义:
\[\arg\max_{h\in\mathbb{SE}(3)}F(h),\quad F(h)=\langle f_X,f_{h^{-1}Z}\rangle_{\mathcal{H}}\]其中\(\langle\cdot,\cdot\rangle_{\mathcal H}\)表示希尔伯特空间中的内积,函数\(f_X\)与\(f_{h^{-1}Z}\)分别定义为
\[f_X(\cdot)=\sum_{x_i\in X}\mathcal{l}_X(x_i)k(\cdot,x_i)\] \[f_{h^{-1}Z}=\sum_{z_j\in Z}\mathcal{l}_Z(z_j)k(\cdot,h_{-1}z_j)\] \[\langle f_X,f_{h^{-1}Z}\rangle_{\mathcal{H}}= \sum_{x_i\in X,z_j\in Z} \langle\mathcal{l}_X(x_i),\mathcal{l}_Z(z_j)\rangle_\mathcal{I} \cdot k(x_i,h^{-1}z_j)\]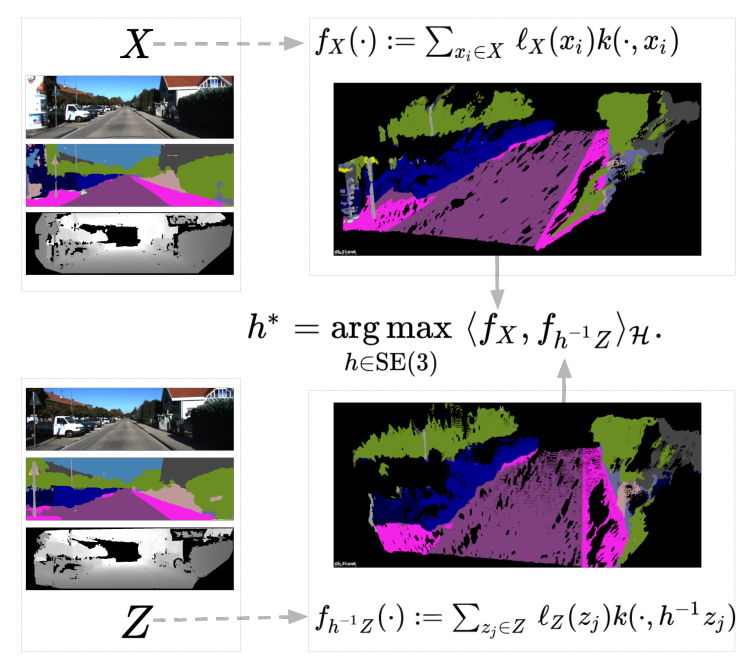
算法性能
纯几何版本的匹配算法可能达到4.55%的位移误差(平均里程计漂移量),高于GICP (11.23%)和NDT (8.50%),加入语义信息之后误差可以进一步降低至3.64%。
当前版本的GPU实现中,匹配少于15k点的点云数据(经过降采样)的平均运算时间为1.4s,而GICP与NDT处理稠密点云(未经降采样,大概包含150k-350k个点)的平均时间分别为6.3s与6.6s。
动态城市环境长期定位
论文提出其中语义点云簇地图的长期LiDAR定位算法。首先,使用CNN神经网络提取LiDAR点云的语义信息,提取出环境中长期稳定的静态杆状物体,并与语义点云簇地图进行配准。当无人车重新进入环境中时,通过对局部地图中的点云簇和全局地图中的点云簇进行匹配,完成无人车的重定位。通过上述方法,在不须维护高精度点云地图的前提下,完成了长期环境中的重定位。
算法流程
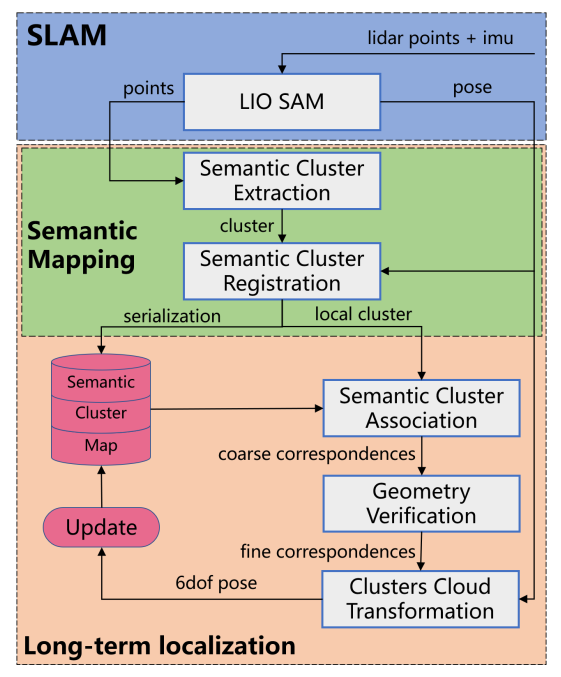
系统包含三部分,即SLAM模块,语义建图模块和长期定位模块。
重定位模块以2Hz的频率输出全局重定位结果,可用于对LiDAR里程计的累计误差进行校正,并将校正后的6-DOF位姿进行实时地输出。
语义点云簇提取:
使用CNN网络RangNet++对点云进行语义分割,获得两种语义类别标签的点云簇,即trunk和pole。
设计点云簇管理器,包含3D中心、2D中心、ID、语义标签、点云数据、内存地址等,如下图所示。
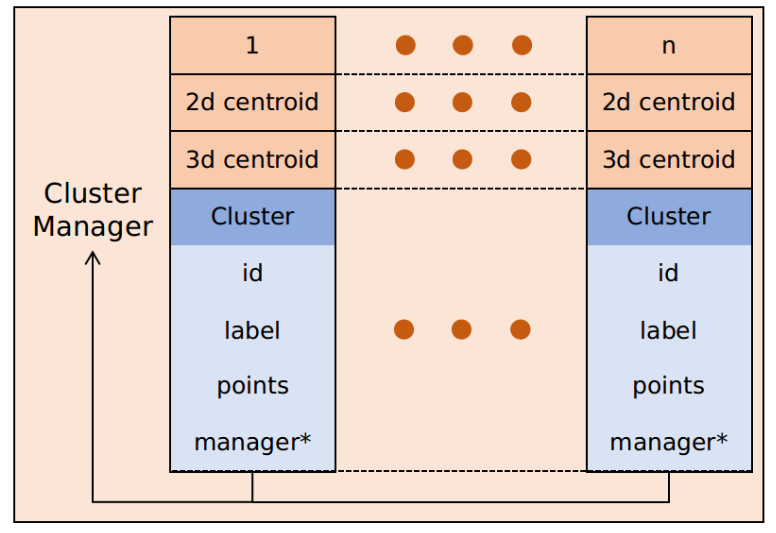
语义点云簇配准:
包含$\(j\)个点云簇的全局点云簇地图表示为
\[\mathcal{M}_g^{cur}= \{\mathcal{C}_{g1},\mathcal{C}_{g2},\dots,\mathcal{C}_{gj}\}\]对于当前帧中的每一个点云簇,先根据SLAM模块(LIO SAM)给出的位姿估计将其投影到全局地图坐标系中,再使用最近邻搜索策略在地图\(\mathcal{M}_g^{cur}\)中搜索其最近邻点云簇,两个点云簇进行融合;若是没有找到近邻的点云簇,则将其作为新的点云簇加入地图中。
长期定位:
- 已知具有关联关系的点云簇,获取其簇中心的3D坐标,接着,使用RANSAC算法过滤错匹配的点云簇,然后使用ICP算法对点云簇中心进行配准。最后,使用得到的变换作为初始值,对点云簇中所有的点进行ICP精配准。长期定位结果以2Hz的频率进行输出,用于对里程计累计误差进行校正。
算法性能
算法在三个自采数据集上的重定位成功率分别达到100.0%、96.6%和98.3%,超过对比算法Scan Context Image(SCI)。
在1.4km规模的地图中,无人车行进距离为24m、30m和43m后,重定位的成功率分别为90%、95%和99%。
三个自采数据集上的定位误差RMSE分别为0.29m、0.34m和0.24m,优于LOAM算法(分别为42.41m、44.32m和40.48m)。
TwistSLAM
论文面向动态环境,提出语义双目SLAM系统(TwistSLAM)。根据语义标签,生成点云簇,使用环境中的静态部分对相机传感器进行定位,并对环境中的物体进行跟踪。论文提出新的跟踪与BA策略,考虑了点云簇之间的连接特性,对位姿的估计进行约束,提高估计精度。
算法流程
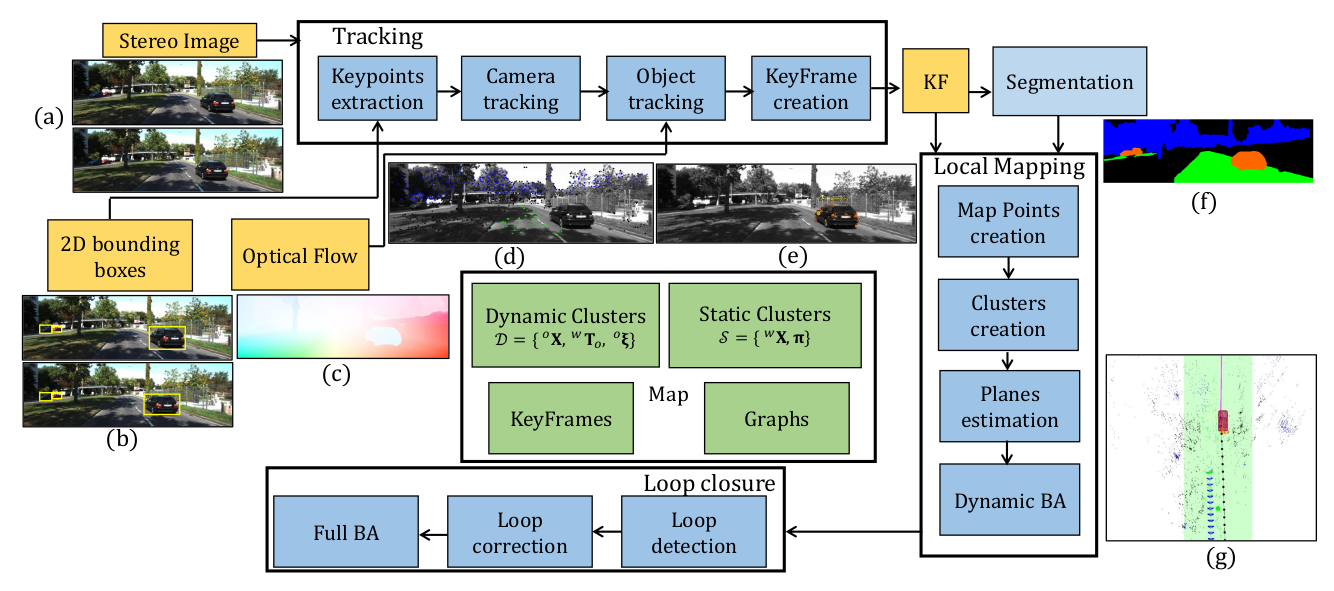
系统使用静态语义点云簇对相机进行定位,并对动态物体上的特征点进行跟踪,接着将相机位姿与动态3D点纳入统一的BA框架进行进一步地优化。
利用语义分割结果生成点云簇:
- 使用detectron2对图像进行语义分割,融合连续多帧的语义标签,将语义ID相同的点形成一个语义点云簇。给定先验信息,即静态点云簇标签(如道路、建筑等)以及动态点云簇标签(如轿车、自行车、行人、公交车等)。
点云簇几何结构信息:
- 对于平面结构的点云簇,使用RANSAC算法进行平面参数的拟合。
动态环境SLAM算法:
对于动态环境,只使用静态点云簇进行相机位姿的计算,通过最小化重投影误差,对相机位姿进行估计。
\[E({}^{c_i}{\bf T}_w)= \sum_{j\in\mathcal{S}} \rho\left( \left\| {}^i{\bf x}_j- p({}^{c_i}{\bf T}_w,{}^w{\bf X}_j) \right\| \right)\]针对动态物体比较多的环境,比如停车场,为了不陷入定位退化的问题,后面会将所有的动态物体与相机纳入一个BA框架中,进行位姿的估计。
动态物体关键点跟踪:
- 使用光流法RAFT对动态物体上的关键点进行跟踪。
点云簇之间的“机械关节”约束:
对于给定先验语义类别,动态点云簇通过特定的“机械关节”连接到一个静态点云簇上。例如平面关节,包含三个自由度,即两个平移自由度和一个旋转自由度,可以用来表示车辆与道路地面之间的连接关系;再如旋转关节,只有一个旋转自由度,可以用来表示门和墙面之间的连接关系。
假设动态物体的速度进行可以用twist $\boldsymbol\xi$进行表示,通过最小化下式进行计算:
\[E({}^{o_i}{\boldsymbol\xi}_w)=\sum_j\rho \left( \left\| {}^i{\bf x}_j- p({}^{c_i}{\bf T}_w\exp({\bf\Pi}{}^w\boldsymbol\xi_{o_i}){}^w{\bf T}_{o_{i-1}}, {}^o{\bf X}_j) \right\| \right)\]
动态BA:
动态BA算法不止考虑相机轨迹与静态特征点的位置信息的联合优化,同时加入动态物体上提取的特征点以及相邻两帧之间的运动约束。
\[E(\{ {}^w\boldsymbol\xi_o, {}^c{\bf T}_w, {}^w{\bf X},{}^o{\bf X} \})= \sum_{i,j}e^{i,j}_{stat}+ \sum_{i,j}e^{i,j}_{dyna}+ \sum_{i}e^{i}_{const}\]其中$e^i_{const}$表示两帧twist之间的运动约束。
\[e^i_{const}=\rho \left( \| {\bf\Pi} {}^w\tilde{\boldsymbol\xi}_{o_{i+1}} -{\bf\Pi} {}^w\tilde{\boldsymbol\xi}_{o_{i}} \|_{\bf W} \right)\]
算法性能
实现车体定位的同时,完成对动态物体的跟踪以及速度估计,在图像中对动态物体速度进行输出,并在三维空间中给出动态物体的定位及轨迹结果。
在KITTI数据集21个序列上的平均RPE平移误差为0.04m/f,旋转误差为0.034deg/f,优于ORB-SLAM2(0.055m/f, 0.046deg/f)。
实时性能较差,且需要GPU支持。
异步多视角SLAM
论文:Anqi Joyce Yang, Can Cui, Ioan Andrei Bârsan, et al. Asynchronous Multi-View SLAM. ICRA, 2021.
目前多数多相机SLAM系统都假设所有相机数据采集过程的同步性,而实际应用中通常不易满足这样的假设。论文针对这样的问题,面向相机跟踪、局部建图以及闭环检测应用,提出融合连续时间模型的异步多帧信息关联策略。通过覆盖482km路径的异步多相机移动平台自采数据集AMV-Bench,对论文算法进行测试和评估。
算法流程
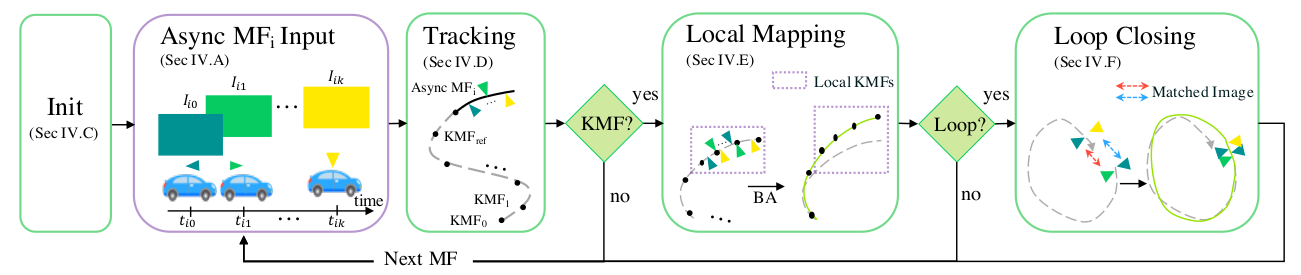
AMV-SLAM系统包含VSLAM系统中的三个线程,即相机跟踪定位、局部建图和闭环检测,并通过异步多帧组合策略以及连续时间运动系统泛化至异步多传感器系统。
异步多帧组合策略:
- 将采集时间接近(例如100ms内)的图像帧组成一组(key multi-frames, KMF),每个异步多帧组合都包含:(1) 图像-时间戳序列\({(I_{ik},t_{ik})}_{\forall i}\),以及 (2) 用于恢复轨迹的连续时间运动模型的参数。
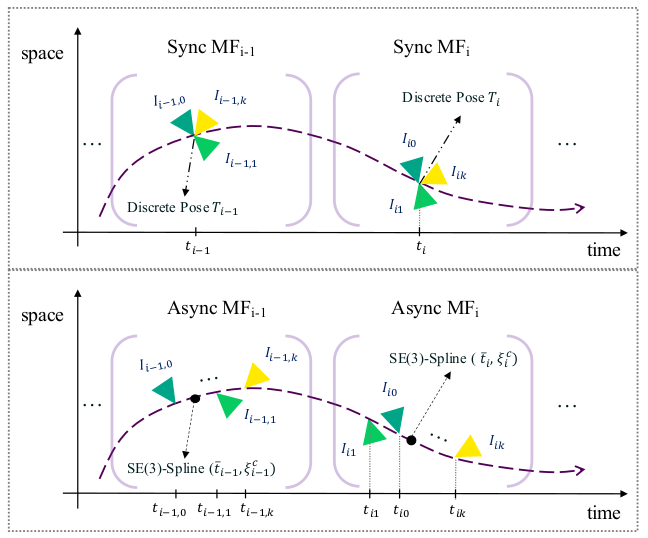
连续时间轨迹表示方法:
- 为了通过观测时间的机器人位姿表示任意时间的轨迹信息,将机器人轨迹表示为连续时间函数\({\bf T}_{wb}(t):\mathbb{R}\rightarrow\mathbb{SE}(3)\),然后采用三次B样条曲线对轨迹进行拟合,其中样条曲线的控制点选择为关键帧序列中所对应的位姿。
系统初始化:
- 当具有足够大小重叠区域的相机在足够相近的时间采集到图像时,即可对系统进行初始化。
跟踪定位:
- 在跟踪的过程中,估计当前采集的多帧图像组相对于关键帧图像组的位姿,并决定是否加入新的关键帧组进行地图更新。在跟踪定位中,使用连续时间线性模型\({\bf T}^l_{wb}(t)\)对相机轨迹进行估计,具有更高的时间效率,并将其用作后面三次B样条曲线的初值。用线性插值的方法得到相机位姿初值后,再通过最小化重投影误差的方法,对位姿结果进行优化,并纳入RANSAC框架使结果更鲁棒。
局部地图构建:
- 在局部建图模块中,首先使用三次B样条曲线对局部轨迹进行优化,接着使用BA算法对控制位姿与地图点进行优化。
闭环检测:
- 在闭环检测中,对DBoW3算法进行拓展,增加多视角相似度检验以及多视角几何检验。
算法性能
在论文发布的数据集上,AMV-SLAM系统可以达到0.35cm/m的RPE平移误差,1.13e-5rad/m的RPE旋转误差,6.13m的ATE误差,以及92%的定位成功率,优于ORB-SLAM2系统(分别为1.85cm/m, 3.29e-5rad/m, 30.74m, 77.33%)。
目前AMV-SLAM系统不支持实时运行。
基于3D语义共视图的闭环检测
传统闭环检测方法多数是基于低层几何或图像特征,可能会导致模糊性,无法区分相似场景,产生错误的闭环。一些研究在闭环检测中考虑了图像的2D语义信息,但很少将3D场景的语义信息融入语义SLAM系统。论文提出SmSLAM+LCD方法,在语义SLAM系统中结合高层3D语义信息和低层特征信息,进行精确的闭环检测。
系统架构
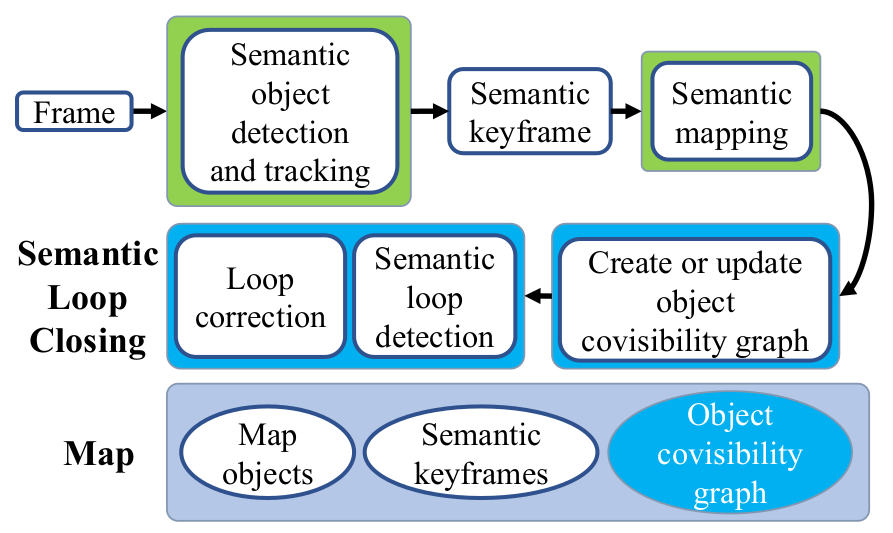
SmSLAM+LCD系统包含语义目标检测和跟踪、语义建图、语义闭环检测三个主要模块。
语义检测和跟踪模块对系统输入的单目图像进行处理,使用ORB-SLAM2中的跟踪模块作为视觉里程计,使用YOLOv3进行目标检测,对目标区域进行ORB特征点提取,生成BoW向量对目标物体进行描述,并进行目标级的数据关联对当前帧提取的目标与地图中的物体进行匹配。
语义建图模块在生成新的语义关键帧时,对当前地图进行更新,加入新的关键帧,并更新地图中物体与语义关键帧之间的关联信息。
语义闭环检测模块将语义目标组织成语义共视图的形式,并对其进行更新,基于此完成闭环的检测。
闭环检测算法流程:
语义共视图:
共视图的节点是地图中3D语义路标,节点信息包含:
地图语义路标外接椭圆的主轴的长度\(l_a,l_b,l_c\);
语义路标中心点坐标\(t\);
节点存储语义类别的概率分布\(p\in\mathcal{D}(\mathcal{L})\),对于给定语义类别\(z\),当前节点属于类别\(z\)的概率为\(p(z)\);
可以观测到当前路标的关键帧集合;
关键帖图像上包含当前路标的图像块计算得到的BoW特征集合。
当两个节点在同一语义关键帧中同时出现至少三次时,就在这两个节点之间添加一条边。当添加新的关键帧时,对语义共视图进行更新。
语义闭环检测:
确定候选闭环:通过相似度评分的大小进行候选闭环的选择。
节点匹配:节点相似度定义为
\[s_n(i,j)=s_a(i,j)\cdot s_c(i,j)\]\(s_a(i,j)\)为视觉相似度,\(s_c(i,j)\)为语义类别相似度,定义为类别分布之间的巴氏距离
\[s_c(i,j)=\sum_{z\in\mathcal{L}} \sqrt{p_i(z)p_j(z)}\]通过二分图最大匹配问题进行节点的匹配:
\[\max_{x(i,j)\in\{0,1\}} TS=\sum^{|V_c|}_{i=1} \sum^{|V_l|}_{j=1} s_n(i,j)x(i,j),\\ {\rm s.t.} \sum^{|V_c|}_{i=1}x(i,j)\le1,\forall j; \ \sum^{|V_l|}_{j=1}x(i,j)\le1,\forall i.\]SIM(3)变换计算:根据节点匹配结果,使用RANSAC算法进行SIM(3)变换的计算,接着,用低层点特征对SIM(3)变换的求解结果进行优化。
算法性能
在TUM数据集的两个序列(fr2/desk, fr3/office)上均能达到100%的准确率,高于ORB-SLAM2和ORB-SLAM3中所使用的闭环算法;
在fr2/desk和fr3/office序列上的RMSE轨迹误差分别为1.4cm和1.6cm。